Set Up Jupyter Notebook and Client Library for Document Classification
- How to install Python and Anaconda
- How to set up a local JupyterLab instance



In order to give you a head start, a client library for the Document Classification service is available. The library already has all necessary operations implemented and ready to use, like, for example, Creating a Dataset and Training a Model. The client library can be found here.
Additionally, a Jupyter Notebook is used in the following tutorials to make the steps interactive and easy to follow. For more information on Jupyter Notebooks, see Jupyter. The notebook that was created for this tutorial mission is also available in the client library repository.
- Step 1
First, you need to install Anaconda. Anaconda is a platform that offers tools to process large datasets and is often used by data scientists. When installing Anaconda, the programming language Python is installed as well.
If you are on Linux, there is a script available for the installation of Anaconda here. The first three commands are necessary to install Anaconda whereas the other commands are used in the following step of this tutorial.
If you are on a different operating system or the script does not work for you, head over to the Anaconda installation guide and look for your operating system. Once there, follow the installation guide.

You have successfully installed Anaconda.
- Step 2
As mentioned before, you now need to execute the other commands of the script.
Once the installation is done, enter
jupyter labto start JupyterLab. Once you started JupyterLab, the browser automatically opens the respective web page. Additionally, you can find the URLs in the output in the command prompt as you can see in the image below.
You have successfully installed a local instance of JupyterLab and you are now able to work with Jupyter Notebooks.
- Step 3
As everything is installed now, you can open the Jupyter Notebook that is used in the following tutorials. Therefore, you are going to clone the repository that includes the notebook and the example dataset.
Open JupyterLab in your browser, using the URL from the command prompt from the previous step. Once opened, click the tile under the heading
Notebookto open an empty notebook.Alternatively, you can click File > New > Notebook to open an empty notebook.

In the notebook, click into the first cell and enter the following command:
!git clone https://github.com/SAP/business-document-processing.gitThen click Run. This command clones the repository.
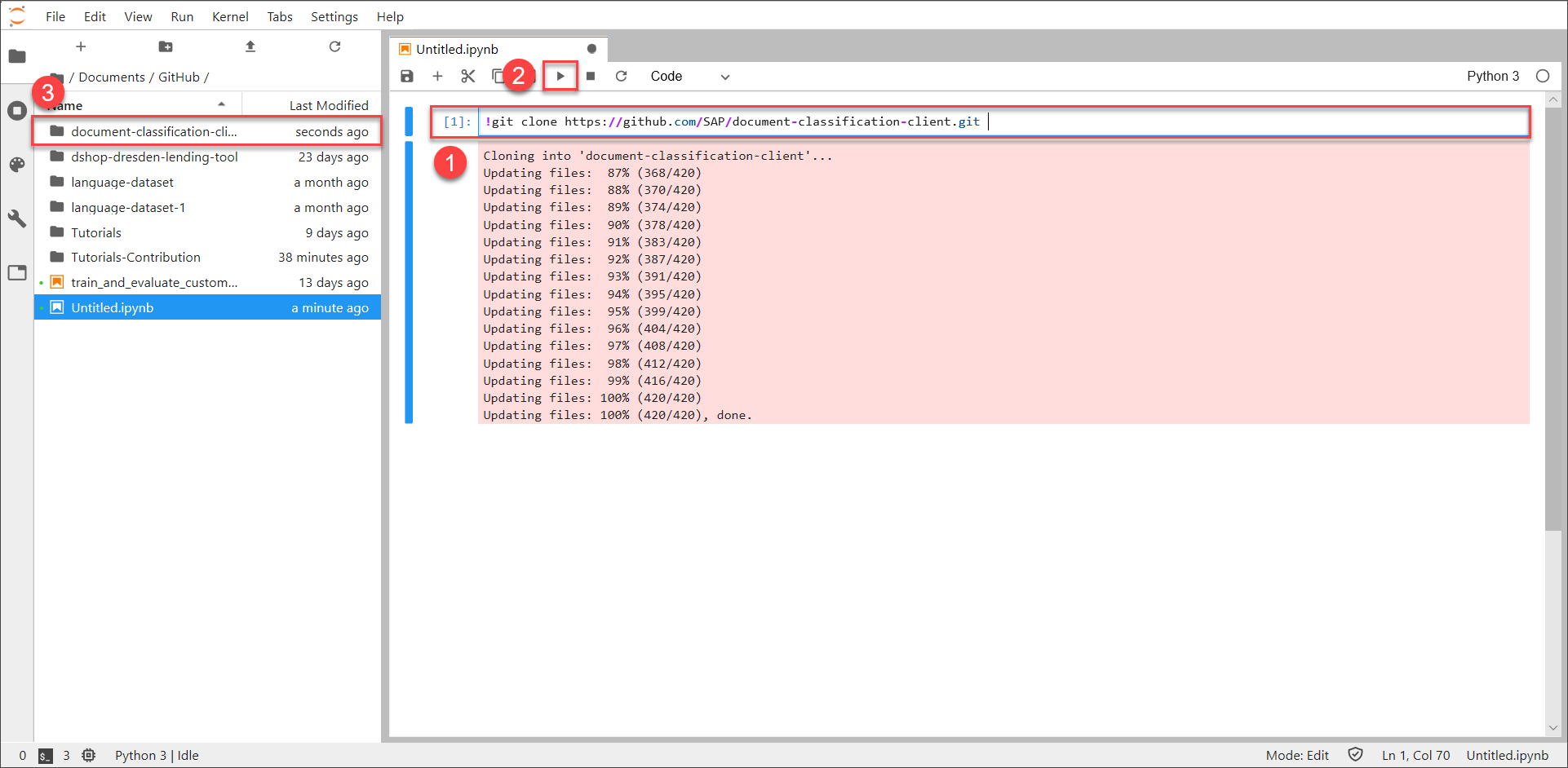
Once everything is done, a folder appears on the left named
document-classification-client. This folder is the cloned repository.Now navigate into the folder
document-classification-client>examplesusing the navigation pane on the left. In this folder the actual notebook, calledtrain_and_evaluate_custom_model.ipynb, is located. Open the notebook by double-clicking it. The content of the notebook will now appear on the right side of the page.
- Step 4
Jupyter Notebooks are interactive playgrounds to code and are often used in data science to explore datasets.
Notebooks contain a number of cells in a sequence whereas each cell mainly contains text or code but can also output diagrams and graphics.
Throughout this tutorial mission, you walk through the notebook and explore the capabilities of the Document Classification service as well as understand the capabilities of Jupyter Notebooks.
